
AI绘画利器:Stable-Diffusion-ComfyUI保姆级教程
AI绘画在今天,已经发展到了炽手可热的地步,相比于过去,无论是从画面精细度,真实性,风格化,还是对于操作的易用性,都有了很大的提升。并且如今有众多的绘画工具可选择。今天我们主要来聊聊基于stable diffusion的comfyUI!
comfyUI具有可分享,易上手,快速出图,以及配置要求不高的特点,comfyUI以节点链接的工作流方式进行绘图,对于整个出图流程也更容易理解。因此comfyUI比较适合与新手入门
一、主流AI绘画工具
说到AI绘画工具,现在应该能找出很多,比较主流的有Midjourney(简称MJ),Stable Diffusion(简称SD),DallE,文心一格,Leonardo.Ai等等
- Midjourney:https://www.midjourney.com/
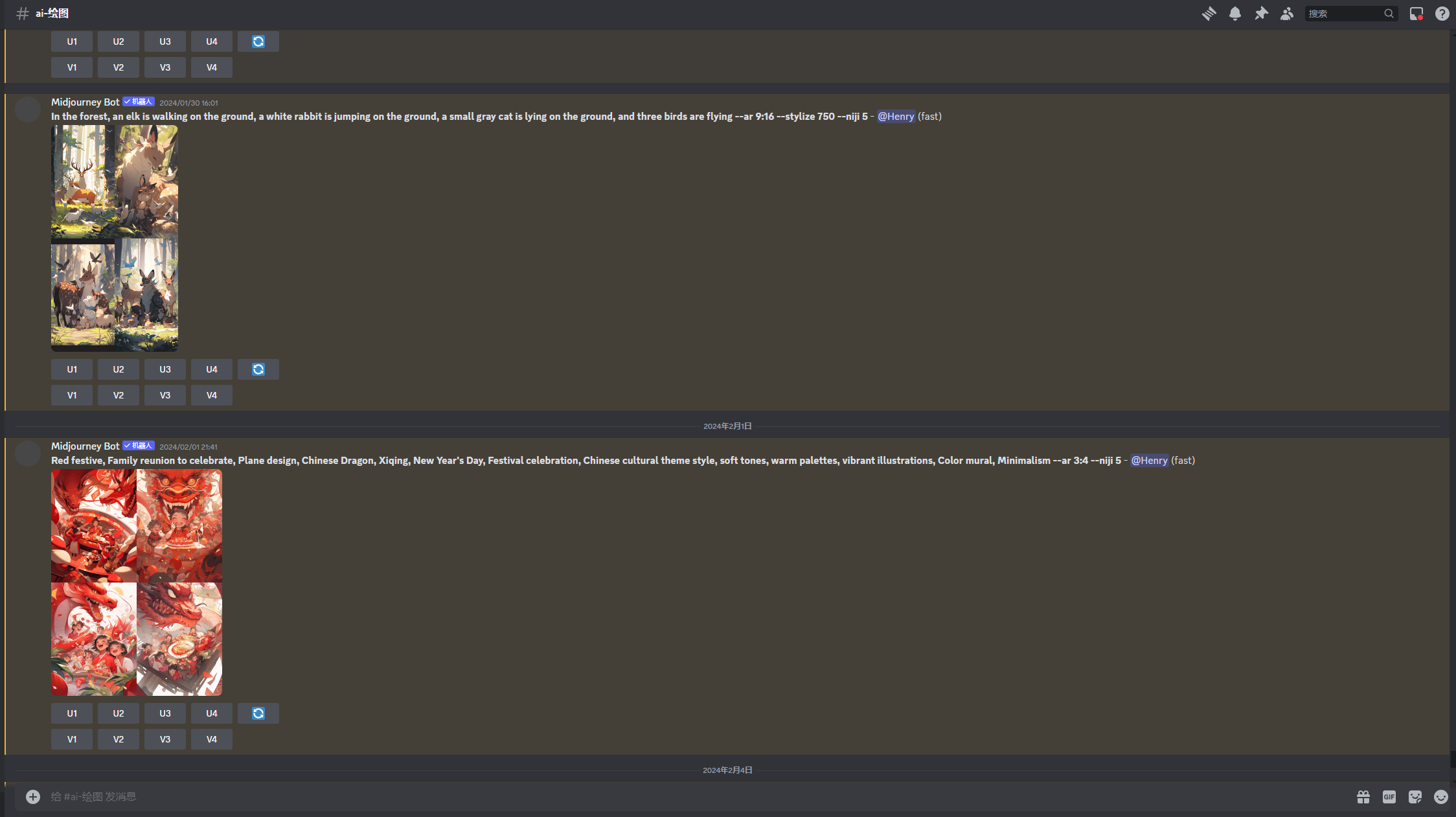
- Stable Diffusion:https://github.com/AUTOMATIC1111/stable-diffusion-webui
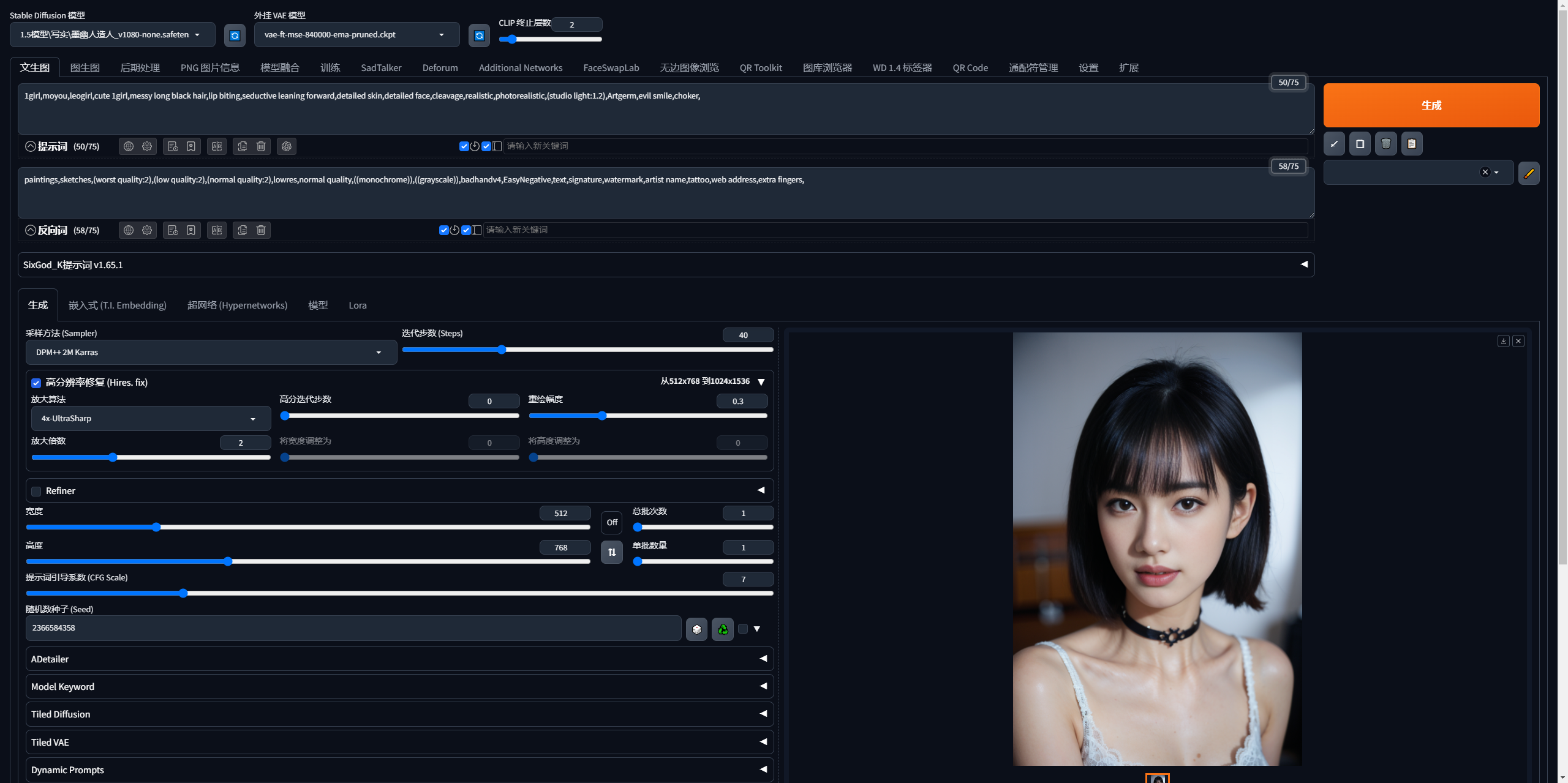
- Leonardo:https://app.leonardo.ai/
我们对主流AI工具做个简单的对比
| 项次 | Midjourney | Stable Diffusion | DallE | 文心一格 | Leonardo |
|---|---|---|---|---|---|
| 是否收费 | 独享帐号根据不同档位需要每月10-30美元(约人民币70-200+) | 开源免费 | 需要开通ChatGPT4来使用,个人费用为每月20美元(约人民币140) | 会员为每月69-339(新账号有免费体验额度) | 普通用户每日5张图的免费额度,会员每个月300多张额度,会员每月10-48美元(约人民币70-300) |
| 是否开源 | 否 | 是 | 否 | 否 | 否 |
| 配置要求 | 浏览器即可访问操作,无需电脑配置 | 本地或云主机运行,对配置尤其是显卡要求高,GPU最好为独显且8G以上显存 | 浏览器即可访问操作,无需电脑配置 | 浏览器即可访问操作,无需电脑配置 | 浏览器即可访问操作,无需电脑配置 |
| 网络要求 | 需要KX上网 | 除了下载插件和模型,其余时间可以本地出图,无需网络 | 需要KX上网 | 国内网络即可流畅访问 | 需要KX上网 |
| 可控性 | 自由度较低 | 自由度较高 | 自由度较低 | 自由度较低 | 自由度较低 |
| 出图效果 | 质量较高,画质优美 | 出图质量与使用者相关,易入门但上限很高 | 质量不如MJ,但也比较优美 | 质量一般 | 质量较高,画质优美,与MJ相当 |
| 学习成本 | 学习成本较低,只需学习咒语(提示词) | 学习成本较高,对SD的出图流程和质量把控需要有较深理解 | 学习成本最低,得益于ChatGPT,自然语言解析力最强,只需用自然语言描述画面 | 学习成本较低,相对于国外工具,中文理解力最高,可以使用中文提示词进行描述 | 学习成本较低,只需学习咒语(提示词) |
还有一些可白嫖的AI绘画站点,大家也可以自行体验一下:
- 神采AI(每月可白嫖100张):https://www.promeai.com/zh-CN
- ImageFX:https://aitestkitchen.withgoogle.com/tools/image-fx
- Meta AI:https://imagine.meta.com/
不同的绘画工具有不同的优劣势,大家可自行探索最适合自己的工具。本文着重介绍Stable Diffusion ComfyUI
二、SD主流 UI
Stable Diffusion因为其开源特性,有着较高的受欢迎程度,并且基于SD的开源社区及教程、插件等,都是所有工具里最多的。基于SD,有不同的操作界面,可以理解为一个工具的不同客户端。目前主流的操作界面有 WebUI和ComfyUI。
-
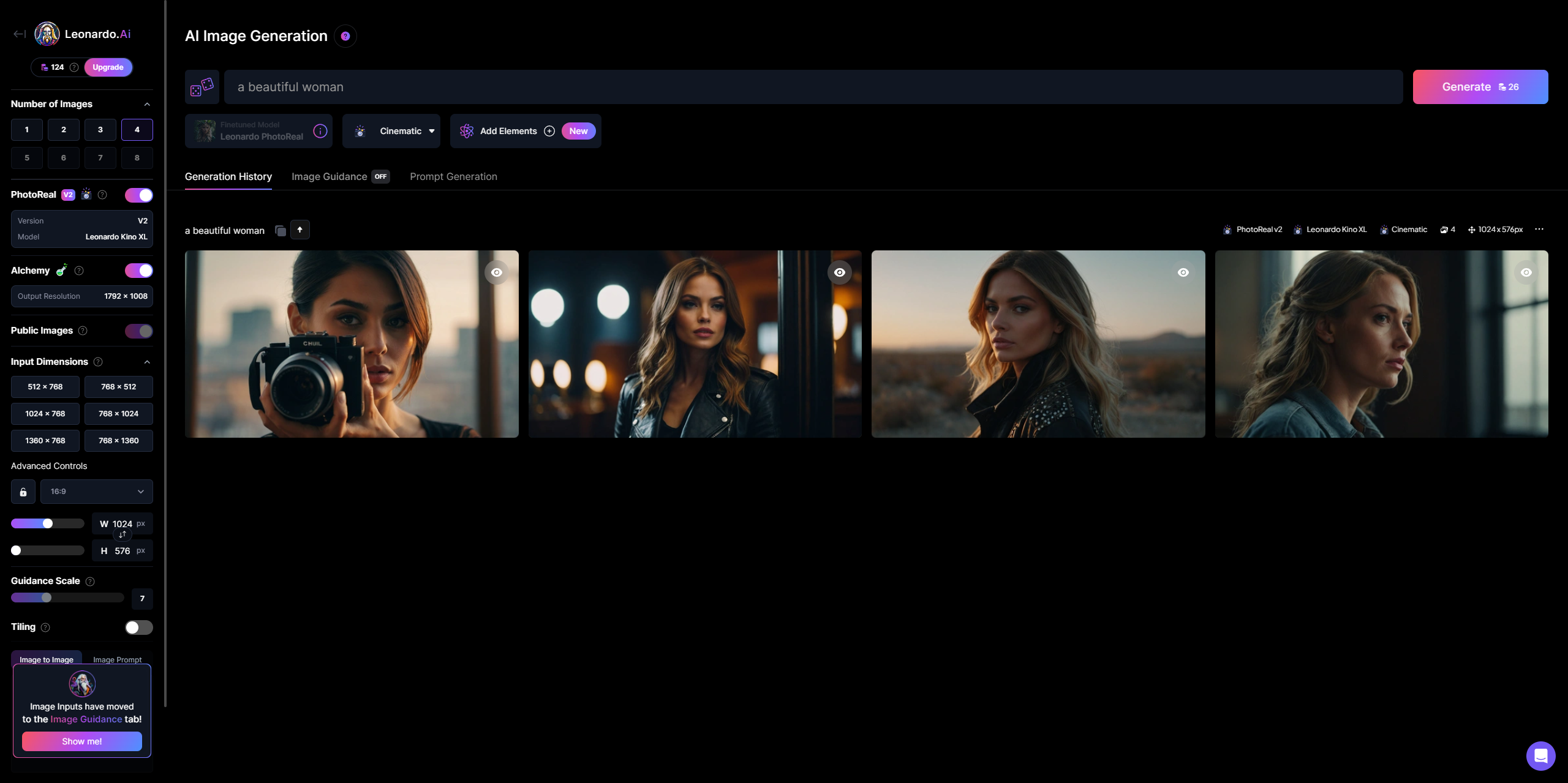
WebUI
优点:界面友好,插件丰富,新手小白基本也能秒上手
缺点:吃显存,对配置要求较高,出图较慢
-
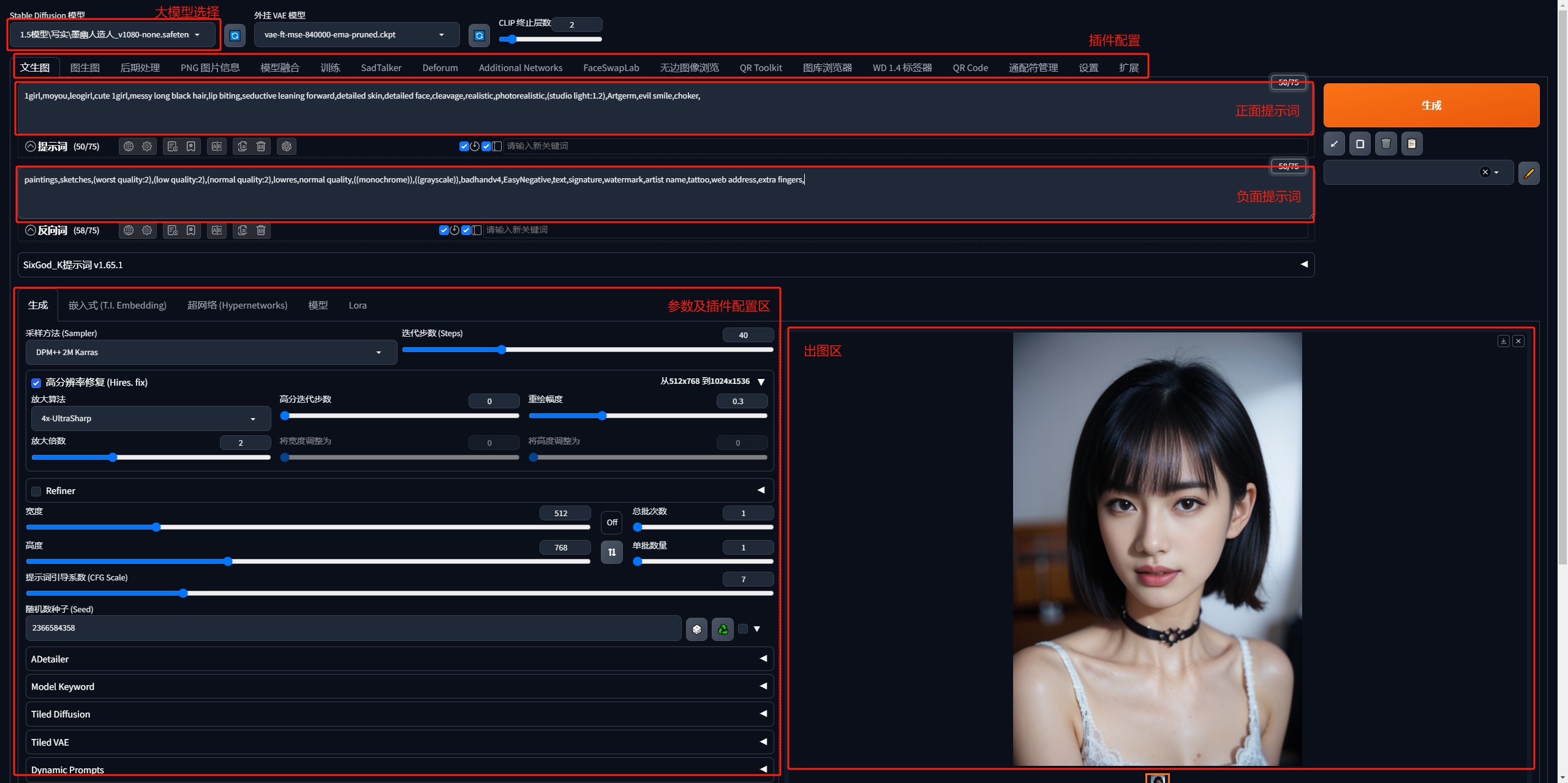
ComfyUI
优点:性能好,速度快,支持工作流的导入导出分享,对小显存友好(GPU小于3G以下依然可以工作),基于工作流,对出图逻辑理解更清晰
缺点:对新手用户不太友好,有一定学习成本
二者各有优缺点,根据自身情况选择即可。我个人更推荐ComfyUI
三、ComfyUI 安装
对于stable-diffusion-webui,我之前有一篇文章有了比较详细的介绍,本文重点介绍ComfyUI的安装部署及使用。
ComfyUI 的节点流程式使用方式,非常便于对SD的绘制过程的理解,并且工作流可以导入导出以及分享,这样对于流程重现以及第三方分享更友好。整体的使用上限更高
详细的安装过程可参考B站详细教程
【【AI绘画】ComfyUI整合包发布!解压即用 一键启动 工作流版界面 超多节点 ☆更新 ☆汉化 秋叶整合包】
https://www.bilibili.com/video/BV1Ew411776J/?share_source=copy_web&vd_source=b8d0b2c4c1a84965a2546f0efe2f5759
1. 安装包说明
ComfyUI 开源地址:https://github.com/comfyanonymous/ComfyUI
对于程序员朋友来说,对于github的使用已经非常熟悉了,但考虑到不熟悉github的读者,以及国内对于github的网络环境的不稳定,除了github的clone之外,也推荐使用秋叶整合包,下载地址放在最后自取。
- 若使用github自行clone项目,需要git、python等必备环境,适合对github已经git和python环境熟悉的朋友使用
- 若使用秋叶整合包,里面包含了所有运行时需要的环境,因此此方法适合与所有人,解压即用
2. 安装文件
网盘(文末自取)中包含以下文件
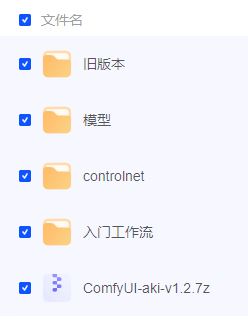
- 旧版本:基本不用管了
- 模型:只有基本的大模型,更多的大模型可自行去国外的C站或国内的liblib站点下载
- contronet:提供contronet所需模型文件,控图必须下载
- 入门工作流:提供基本的入门工作流,导入可直接使用
- ComfyUI-aki-v1.2.7.7z:整合包压缩包,下载后解压即可使用
吐槽 :国内网盘都是坑,没有会员就慢慢下吧
3. 安装步骤
不同于傻瓜式的安装步骤,这里需要稍微做一些配置,主要是配置模型路径
- 配置模型路径
-
这里分两种情况,如果你之前装了webui,并且本身已经下了很多模型了,那么恭喜你,ComfyUI对webui的模型地址做了兼容,可以通过一个配置文件即可与webui共享模型
解压后的根目录,有“extra model_paths.yaml.example”文件,我们对这个文件进行修改
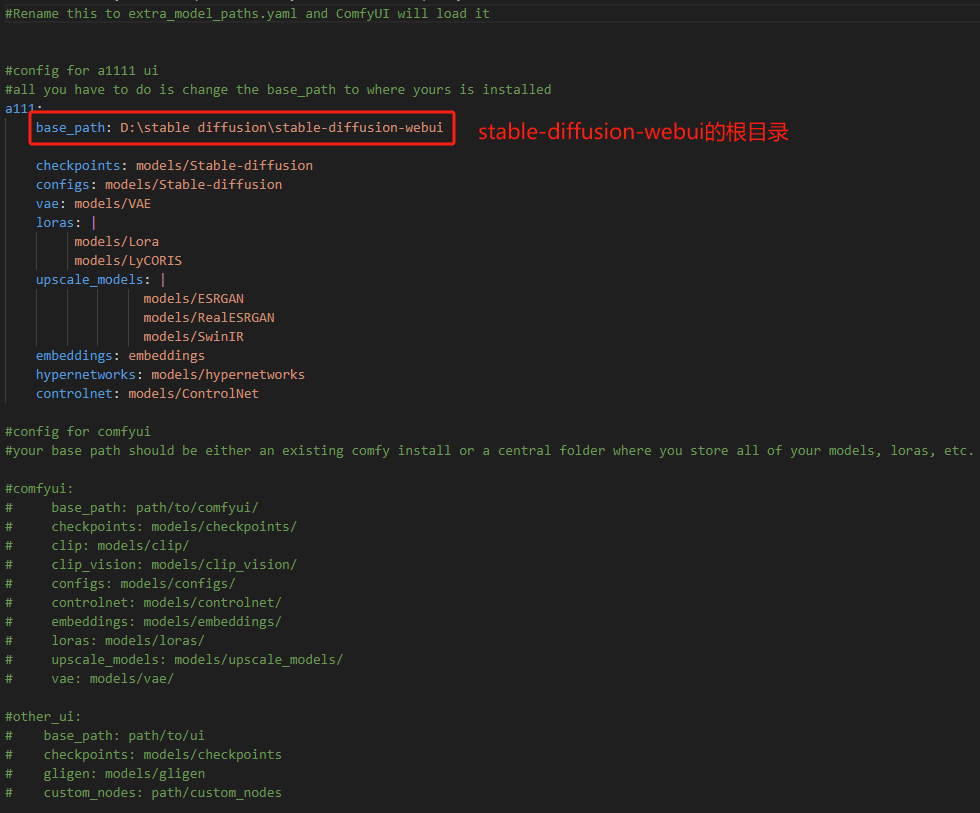
修改完成之后,去掉example后缀,保存为yaml文件即可 -
如果你没有装过webui,即首次使用stable diffusion的话,那么直接解压即可,后续下载的模型只需要放在ComfyUI读取的默认路径即可
| 模型 | 路径 |
|---|---|
| checkpoint模型(大模型) | models/checkpoints/ |
| lora模型 | models/loras/ |
| controlNet模型 | models/controlnet/ |
| vae模型 | models/vae/ |
- 启动
启动“A 绘世启动器。exe”即可。启动后进行主界面,就可以开始ComfyUI的探索之旅了
若是用github自行安装的朋友,还需要下载“插件管理器”,方便后续安装插件(秋叶整合包已经包含了插件管理器),安装步骤如下
分三步:
- 命令行窗口中运行:cd D:\COMFYUI路径XXXX\custom_nodes
- 继续运行:git clone https://github.com/ltdrdata/ComfyUI-Manager.git
- 重启 ComfyUI
4. 汉化
- 整合包可以直接点击右边设置小按钮,并对语言设为中文即可
- 非整合包需自行下载汉化插件,通过插件管理器搜索AIGODLIKE-ComfyUI-Translation安装即可,或类似下载插件管理器的方式在custom_nodes下git clone https://github.com/AIGODLIKE/AIGODLIKE-ComfyUI-Translation.git后重启ComfyUI
5. 学习参考
ComfyUI由于工作流的导入导出的遍历,使得工作流可以互相分享学习,甚至直接使用。目前有很多工作流分享的站点,可以通过导入其他人的工作流进行学习和实践,对自身学习会非常有帮助
ComfyUI官方示例:https://comfyanonymous.github.io/ComfyUl examples
基础工作流示范:https://github.com/cubig/ComfyUI Workflows
基础工作流示范:https://github.com/wyrde/wyrde-comfyui-workflows
comfyworkflows:https://comfyworkflows.com/
esheep(国内站点,访问快):https://www.esheep.com/
6. 插件安装
使用其他人的工作流时,我们往往会发现他们使用了某些我们并没有的节点,导致出现节点缺失的现象,这种情况下,需要我们安装缺失的节点。以下是几种安装插件的常见方式
1、有KX上网环境推荐直接通过界面中的管理器安装缺失节点即可,若没有KX上网,这个过程会很痛苦
2、使用整合包推荐通过启动器安装:版本管理–安装新插件–搜索插件–点击安装
3、单独下载插件:单独下载插件包解压到:comfyui 安装根目录lcustom nodes目录下(与前文提到的安装插件管理器方法一致),然后重启即可。
四、ComfyUI 能干啥?
- 基础文生图
- 基础图生图
- 真人转动漫/动漫转真人
- 线稿上色
- 老旧照片修复
- 隐藏艺术字
- 改变人物姿态
- 四维彩超宝宝长相预测
- 红包封面
- 真人电子AI写真定制
- 赛博朋克风格转换
- 专属表情包
- 手机壁纸
- 更多:这里不一一举例了,类似的玩法在网上可以看到很多,ComfyUI只是一个工具,具体如何应用,就要依靠自身的想象力了
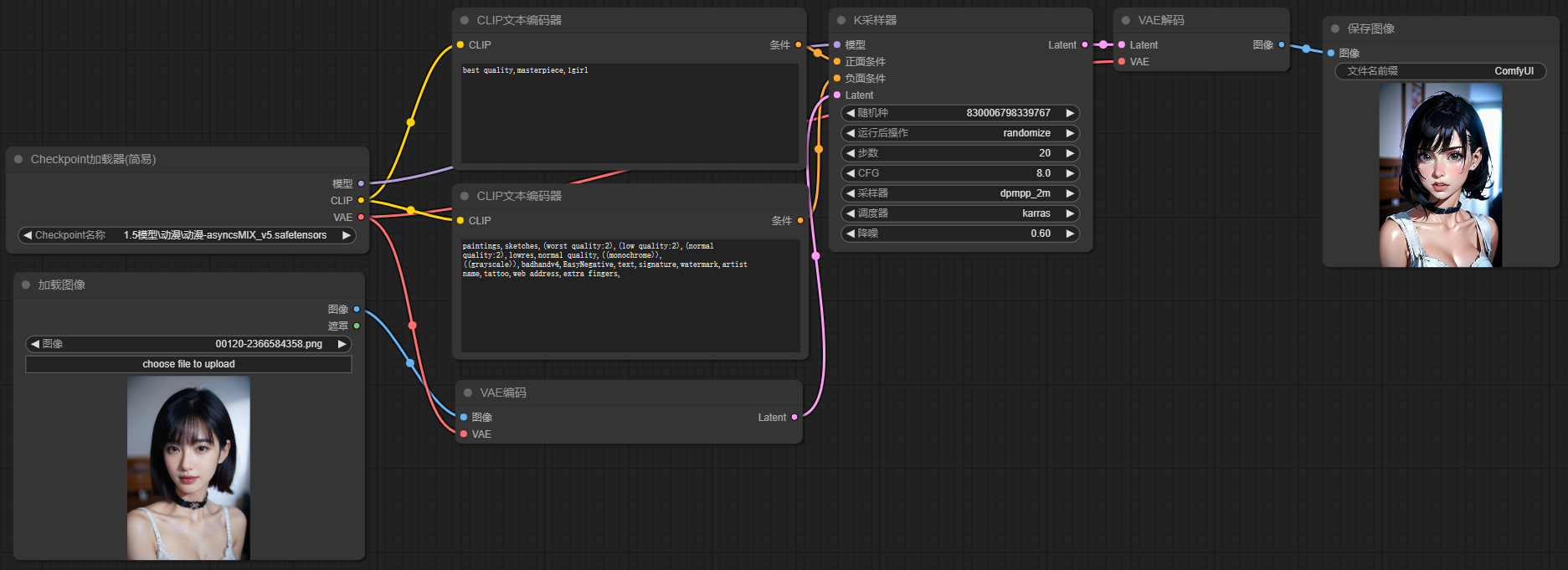
五、默认工作流(文生图)
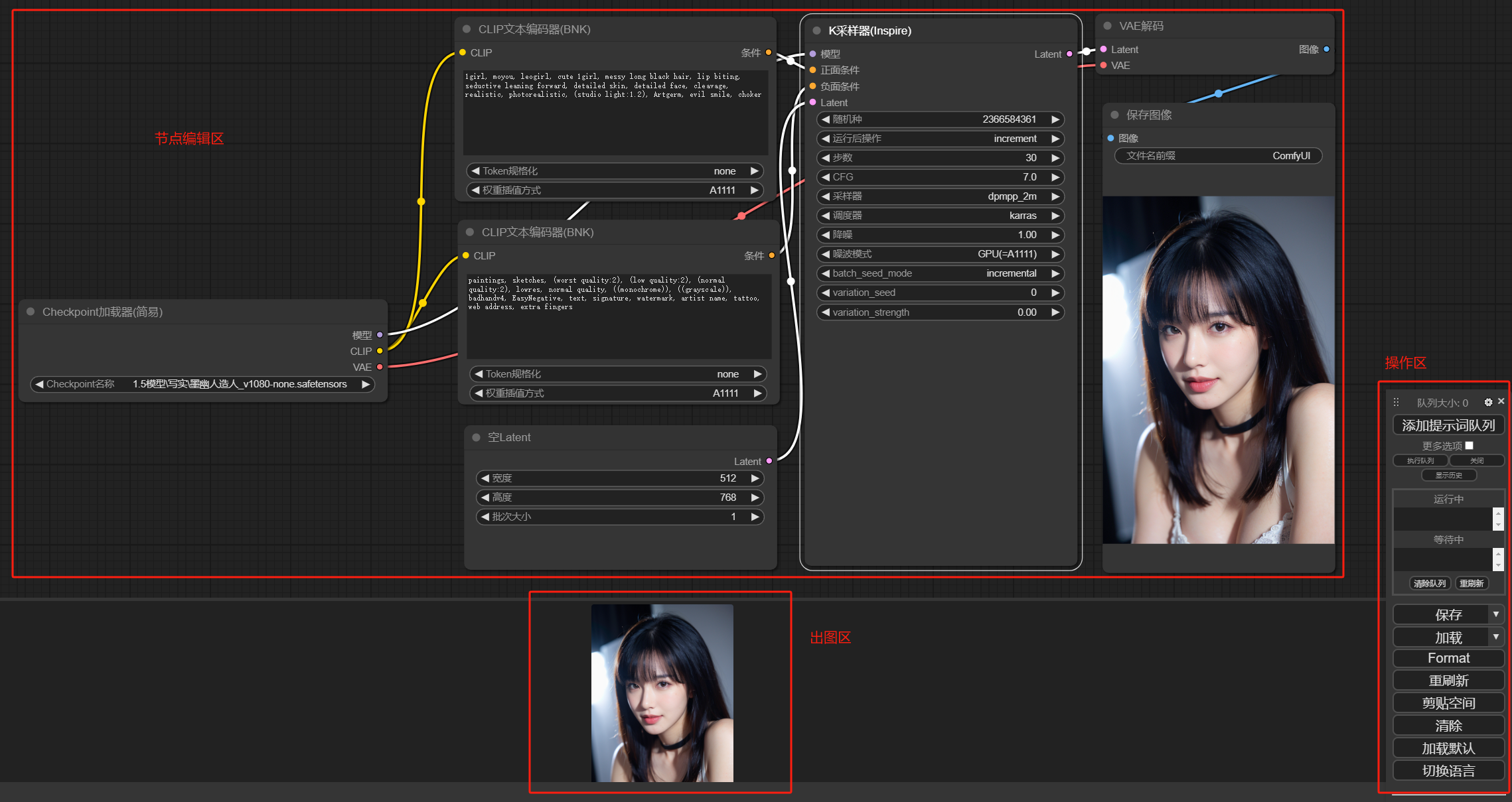
在首次使用ComfyUI时,启动后就可以看到它默认提供的一个工作流,其实就是一个非常基础的文生图工作流,我们就以这个工作对基础节点做个简单的介绍
1、K采样器
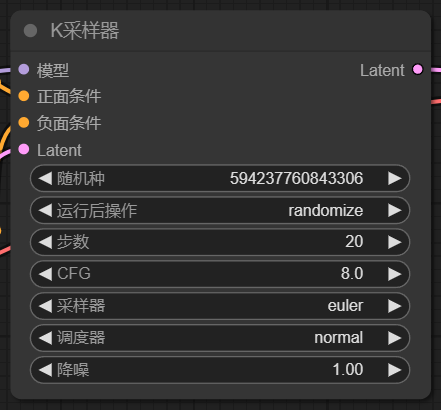
K采样器是SD出图流程中的核心节点,所有节点载入,数据输入,参数配置,最后都会汇总到K采样器,它会结合载入的模型,提示词的输入以及Latent输入,进行采样计算,输出得到最终图像
Latent,即潜空间,可以理解为SD内部流程中的图像格式,如果我们将图像作为输入,则需要通过VAE编码将其转换为Latent数据,在最后输出时,我们也需要通过VAE解码将其转换为像素空间,也就是我们最终图像
2、Checkpoint加载器
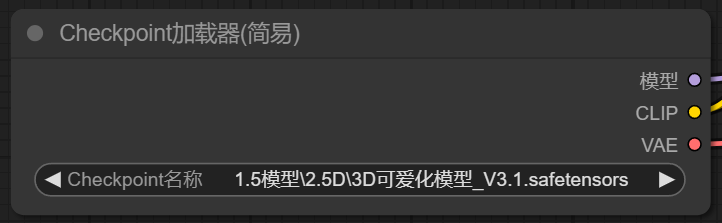
checkpoint 也就是大模型,这个节点是起始点,需要选择相应的大模型,以及vae输入给采样器,clip则连接正反向提示词
其中VAE可以直接使用大模型的vae去链接,也可以单独使用vae解码节点,来选择自定义的vae
3、CLIP文本编码器
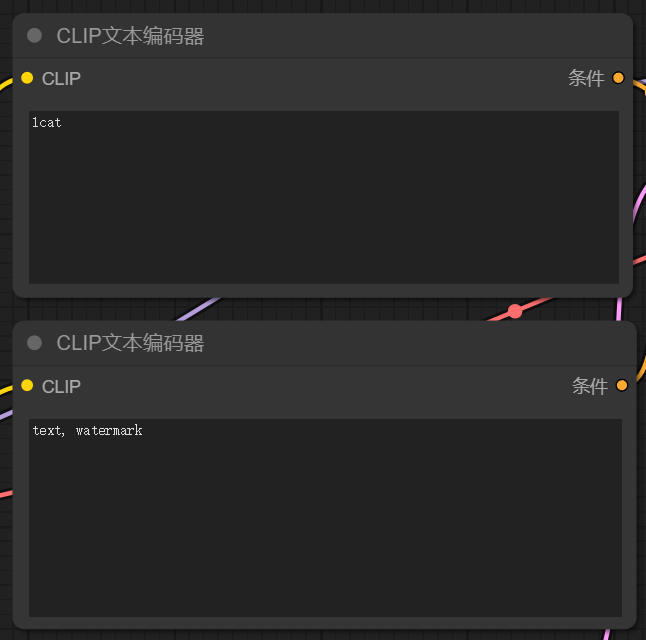
CLIP节点则需要输入提示词,其中CLIP节点需要两个,一个作为正向提示词链接K采样器,一个作为负向提示词链接采样器
4、空Latent
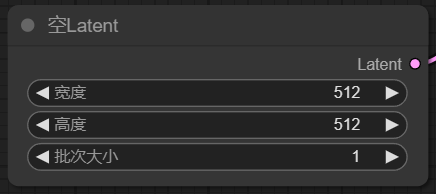
使用空latent建立潜空间图像,这里主要用于控制图像尺寸和批次数量的
5、VAE解码
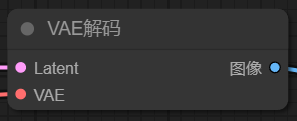
前面已经提到对于Latent潜空间图像和输出的像素图像之间,需要进行一次转换,VAE解码节点则是对这个过程转换的节点
6、保存图像
顾名思义,即保存当前生成的图像,保存的图像除了在当前页面能看到以外,也可以在本地文件夹目录(x:\xxx\ComfyUI根目录\output)下看到所有生成的图片
默认流程整体就这么简单,输入提示词,点击添加提示词队列,即可生成你的第一张ComfyUI图片了

六、图生图工作流
使用过WebUI的小伙伴可能要问了,文生图我懂了,那图生图怎么做呢?其实很简单,加一个图像载入节点作为数据输入就好了。前面提到,像素空间到潜空间需要做一次转换,所以我们就需要“加载图像”和“VAE编码”两个节点。
1. 加载图像
2. VAE编码
通过简单地加两个节点,即把工作流改为了最基础的图生图模式,如以下工作流就是一个简单通过动漫大模型把真人转动漫的工作流,其中K采样器的降噪也就是对应WebUI中的重绘幅度,这个值越大生成图像越靠近提示词,越小则越靠近参考图像,我这里用的 0.6,看情况调整即可


七、Lora
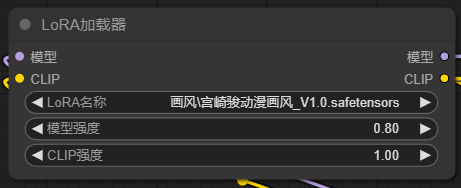
在Stable Diffusion中,Lora可谓是灵魂级别的东西,有了Lora,让模型训练的成本陡然下降,任何人都可以训练出一个自己想要的Lora模型。Lora输入SD中的微调模型,它可以通过训练素材实现主体风格的控制,或画面特征的控制,通过训练Lora,我们可以得到画风Lora,人物Lora,物体Lora等。
lora 是对大模型的后续微调,所以我们在ComfyUI中添加lora只需要在大模型后面新加Lora节点即可
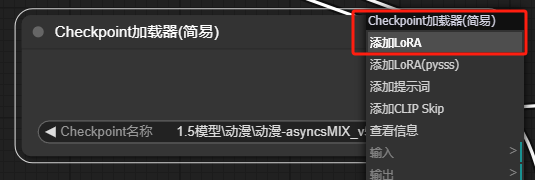
我们可以直接通过右键checkpoint加载节点即可添加lora节点
当然 lora 不仅仅控制风格,可以把人物、衣服等进行炼制,控制出图的人物形象,控制出图人物的穿着都是可以的,这里推荐大家去C站寻宝吧,总有一款你喜欢的,如果没有也可以自己炼制哦。
我们以上面的图生图工作流为例,对整体工作流添加lora节点添加宫崎骏画风lora,于是我们就得到了真人转宫崎骏动漫画风的图片
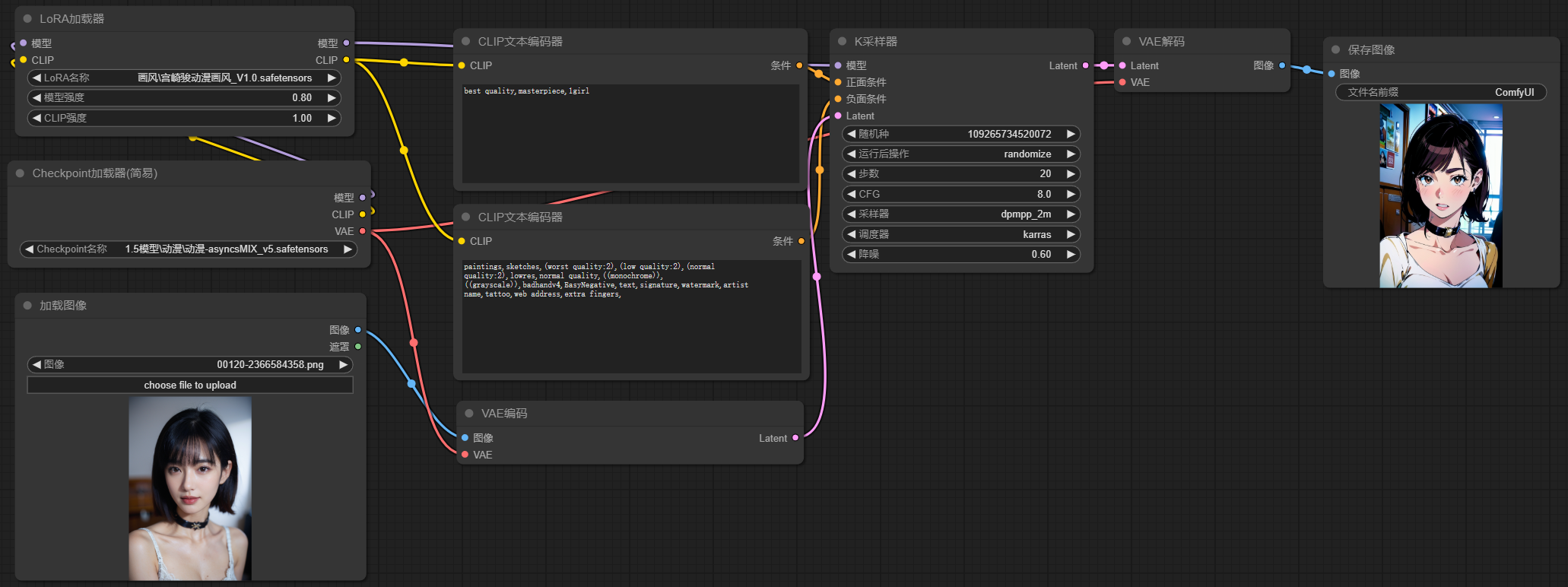

八、ControlNet
SD相比于其他AI绘图工具的强大之处就在于它的控图能力,SD的控图依赖于它的ControNet模型(模型下载参考前文介绍),这是对于使用SD控图不得不得掌握的技能,结合大模型,Lora模型,和ControlNet,三者结合能更好的创造出你所想的画面
ControINet 有独立的控制图像,通过对图像的预处理,再结合提示词进行生成图像
不同的预处理可以对生成的图像进行不同的控制,一般有风格约束、线条约束、姿态约束、景深控制等,不管是WebUI还是ComfyUI,都有强大ControlNet,这里不详细介绍ControlNet,主要讲下如何在ComfyUI中使用ControlNet,后续可能专门写一篇ControlNet的详细介绍
因此,在使用ControlNet时,需要添加几个关键节点:预处理器、ControlNet应用、ControlNet加载器、加载图像、预览图像、VAE解码
1. 预处理器
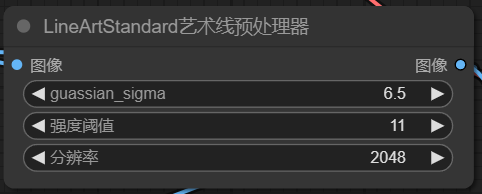
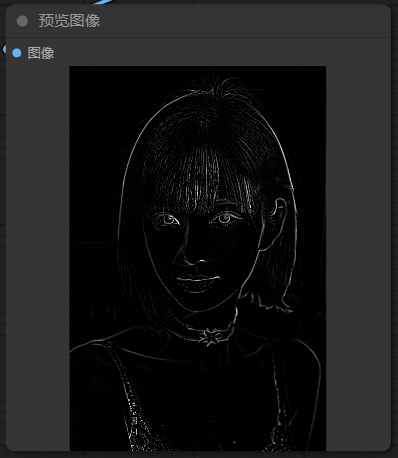
预处理器的作用是选择需要对图像进行的控制方向,这里我们里线条控制为例,让预处理器导出一份预览图像,这样我们能直观的看到预处理的结果
2. ControlNet加载器
ControlNet加载器则用于加载我们需要控图的模型,与预处理器对应就好,前面我们选了线条处理,所以这里我们使用线条的加载器“control v11p sd15 lineart.pth”
3. ControlNet应用
ControlNet应用则用于把正想提示词、预处理器、以及加载器进行统一应用的节点,相当于中间连接器
以下则是一个通过文生图+ControlNet线条控制进行真人转动漫的工作流
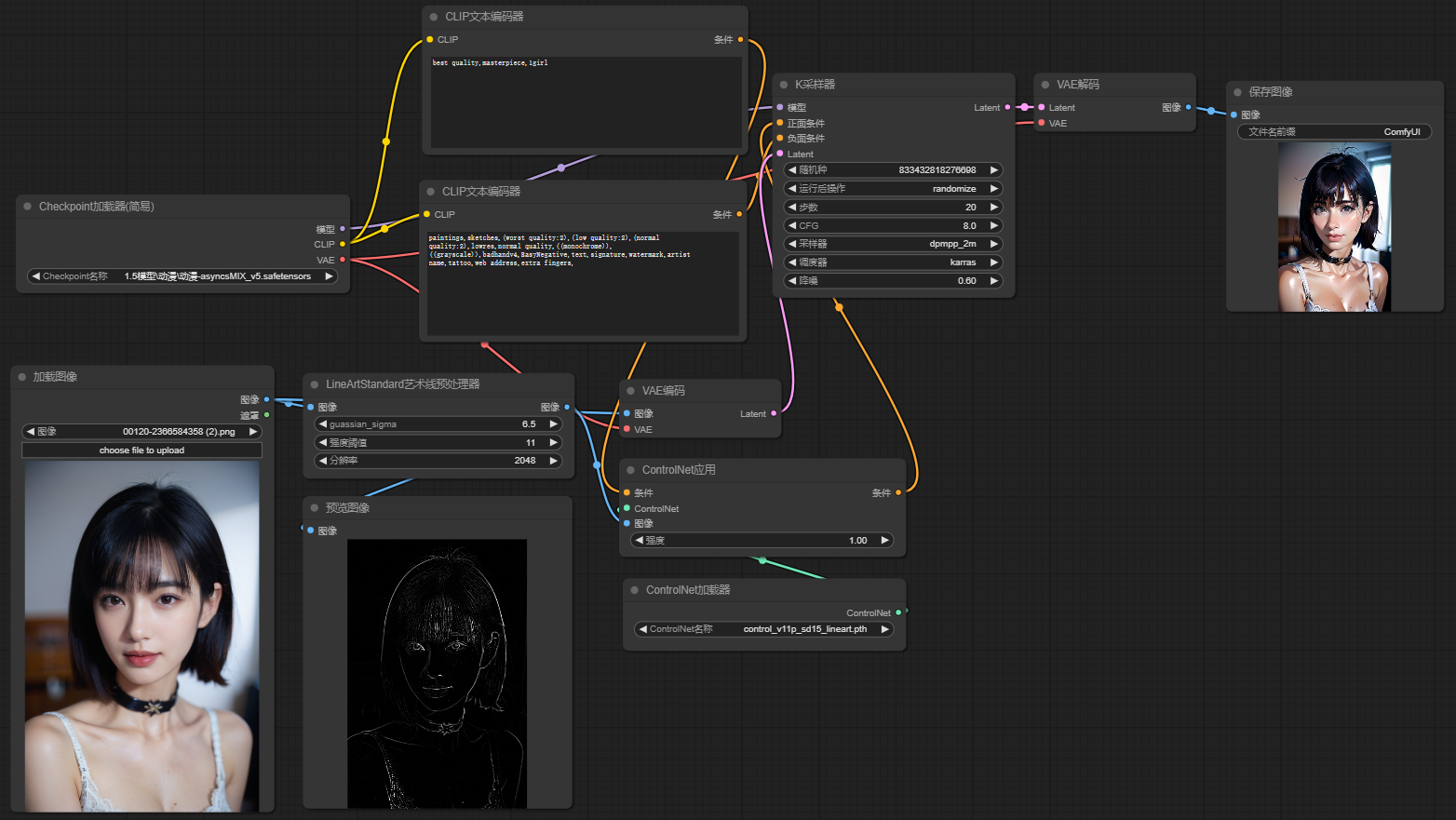
没错,真人转动漫可以直接图生图,也可以通过文生图+ControlNet进行控图转换,使用ControlNet转换的好处在于可以对图片细节进行更加精细的控制,比如我使用线条处理,那么最后出图效果会更加基于原图的线条来生成
九、资源下载
1. 工作流
大家可以在我前面提到的站点下载别人分享的工作流来学习实践,我这里也存了一些常用的工作流
链接:https://pan.baidu.com/s/1lnZo13IuvE8WotFWRgCeOQ?pwd=0wfs
提取码:0wfs